Ola para você que resolveu dar uma olhada nessa postagem. Hoje decidi compartilhar com os leitores alguns livros que já li ou estou lendo que fala sobre Machine Learning.
Acredito que uma das melhores maneiras, depois da prática é claro, de aprender Machine Learning é lendo bons livros. Pois geralmente os livros sempre trazem uma ideia bem definida sobre o tema e algumas discussões e aplicações por isso se você quer entender realmente do assunto um bom livro é indispensável.
Agora sem mais delongas vamos a nossa lista de hoje.
Apesar de ainda esta em fase de acabamento você pode ter acesso ao rascunho de maneira gratuita, mas não se engane, por mais que esteja inacabado ele é uma introdução excelente ao assunto.
O único problema é que para realmente entende-lo além de saber inglês é necessário uma boa base matemática. Mas mesmo para quem tem problemas em matemática já pode ir conferindo os dois primeiros capítulos para ter acesso a insights geniais sobre o tema.
Meu conselho é ler os primeiros dois capítulos e depois ir pegando a base matemática sobre demanda para ir entendendo o resto.
Programing colective inteligency: Se você já programa em Python esse livro é para você. São 11 capítulos de pura aplicações praticas e você não só vai aprender como aplicar os algoritmos mas também como conseguir os dados por meio de Crawlers ou APIs e também visualizar os modelos usando algumas ferramentas interessantes.
Os algoritmos são feitos quase que em puro Python o que nos dar uma oportunidade de entender o comportamento dos modelos passo a passo, sem contar que o autor manda muito bem em programação funcional.
Meu conselho é ler esse livro em conjunto com um livro teórico pois você conseguira assimilar muito melhor os algoritmos e saber relativamente a fundo como cada um funciona.
Bulding Machine Learning System with python: Curto e pragmático. É o que tenho a dizer sobre esse livro não aconselho a usa-lo como introdução a não ser que você já saiba o que esta fazendo.
Esse é um guia essencial para todos aqueles que já querem partir para pratica com os algoritmos.
A ideia é simples: Consiga os dados, Armazene os dados, Prepare os dados, Analise os dados e depois ponto fit e ponto predict se você começou a entender o principio é porque já estar na hora de ler esse manual.
Meu conselho é ler esse livro apenas depois que você tiver pelo menos conhecimento médio em Python, NumPy e Matplotlib e com uma boa carga teórica. Por outro lado não ira absorver nem 20% do conhecimento desse livro.
The Lion way to machine learning:Aconselhado apenas para quem tem bastante experiência com matemática e análise de algoritmos. Ainda não li nem 30% mas o que já vi me agradou e muito é um livro ideal para quem planeja pegar conceitos teóricos e trazer para pratica.
É um livro paradoxalmente prático pois apesar de se expressar usando uma linguagem extremamente simbólica nos deixa aptos a modelar e diferenciar uma série de problemas que surgem quando resolvemos aplicar Machine Learning.
Mais uma vez aconselho esse livro apenas para quem realmente quer se aprofundar no assunto e mesmo assim mais como uma fonte de consulta do que um livro teórico.
Machine Learning in action: Livro genial e prático você ira aprender os 10 algoritmos mais usados em Machine Learning e de quebra aprender um pouco de Numpy e Matplotlib.
Aconselho que antes de ler esse livro tenha uma boa base de numpy e Matplotlib pois o autor não perde muito tempo explicando isso.
Esse é um livro indicado para quem já tem alguma noção do assunto e se sente preparado para encarar os algoritmos de frente. O único problema que vi nesse livro foi uma errata no primeiro capítulo mas não acredito que foi corrigido nas futuras edições.
É um livro que não pode faltar na coleção de quem planeja se tornar um engenheiro de Machine Learning.
A introduction to Statistical learning: Existem duas versões do livro, um totalmente teórico e outro com aplicações em R. É um livro extremamente denso porem extremamente vasto e bem fundamentado. É introdução aos fundamentos teóricos por traz do Machine Learning, mas confesso que ainda passo bastante tempo tentando entender alguns conceitos quando o uso como base de consulta.
É um livro que indico para quem tem um mestrado ou Phd em Matemática, Estatística, Engenharia ou áreas afim. Com certeza quem assimilar esse livro ira ter uma base respeitável no assunto e quem sabe poderá chegar ao estado da arte em Machine Learning.
Neural Networck Design:Mil e dose paginas de puro insight, é um livro que uso como consulta quando já estou sem saída, apesar de ser bem menos denso que o anterior, ainda assim é um desafio para quem não estar acostumado a lidar com matemática aplicada.
Mas não se assuste ele não tem tantas páginas em vão, ele também te introduz nos conceitos matemáticos necessários para entender os tópicos do livro. Mas mesmo assim não aconselho a se aventurar sem uma boa base de Álgebra linear
Infelizmente não posso falar muito pois mal li 3 capítulos do mesmo. Mas gostei e muito do que vi. .
Muito bem. O post de hoje fica aqui. Ainda tenho muitos livros na fila para ler mas como não posso dar uma opinião segura sobre os mesmos não coloquei aqui.
O modelo Decision Tree é muito famoso para utilização em classificação. Porem o que pouca gente sabe é que esse modelo também apresenta bons resultados em problemas de regreção.
Caso tenha pouco entendimento sobre esse modelo aconselho a dar uma lida nos posts abaixo.
Porem antes vamos definir o que é uma regressão no nosso contesto. Existem várias explicações e definições para o assunto, de uma olhada no wikipedia caso queira se aprofundar.
Mas para nosso contesto definiremos regressão como o ato de classificar um valor continuo com base em uma instância ou vetor.
Para quem já entende de Álgebra linear seria como uma transformada de para . Espero que tenha ficado minimamente claro a tarefa de hoje, caso não, continue lendo o post que as coisas darão uma clareada.
Exemplo de regressão linear simples
Em outras palavras: No contexto de Machine Learning Regressão é o nome dado ao ato de se associar um valor continuo a uma instância.
A principal diferença entre classificação e regressão é que enquanto na primeira as classes pertencem a um conjunto finito na segundo temos classe pertencendo a um conjunto infinito, geralmente dentro de um intervalo, mesmo assim com valores heterogêneos demais para serem contados.
Com isso definido vamos ao que interessa. Primeiramente precisamos de um Dataset para trabalharmos. Hoje eu trouxe um Dataset fictício que mostra variação no preço de uma ação semanalmente de acordo com 3 índices: variação no IPCA, variação no índice Ibovéspa e variação do Dólar.
Queremos saber a variação no preço de uma ação em função da variação desses índices.
O conjunto todo tem 25 instâncias separei 20 para treino e o resto deixarei para teste.
Uma vez tendo nossa tabela em mãos a missão agora é construir uma árvore que consiga nos dizer com maior precisão possível qual será a variação no preço da ação com base na variação desses três Índices.
Para quem já sabe o que é uma Decision tree a ideia é muito simples vamos substituir o score de referencia que geralmente é para classificação como Entropia ou Gini impurity por um que consiga lidar melhor com variáveis contínuas como Média e Variância por exemplo.
A maneira que escolhi para construir a árvore não a ideal, ainda mais para conjuntos de dados pequenos. Mas a missão aqui é te mostrar de maneira intuitiva como o modelo se desenvolve por isso usaremos esse método pela simplicidade.
Caso se interesse em aplicar o conceito te aconselho a não fazer exatamente dessa forma na prática pois existem vários detalhes que devem ser analisados, como instâncias, ruídos, quantidade ideal de dados, o tipo de distribuição probabilística do conjunto e mais um bocado de coisas.
Treinar um algoritmo para regressão com poucos dados é um pouco complicado pois pode não haver amostras o suficiente de uma determinada instância para o algoritmo captar padrões mais relevantes o que pode deixar as predições fracas.
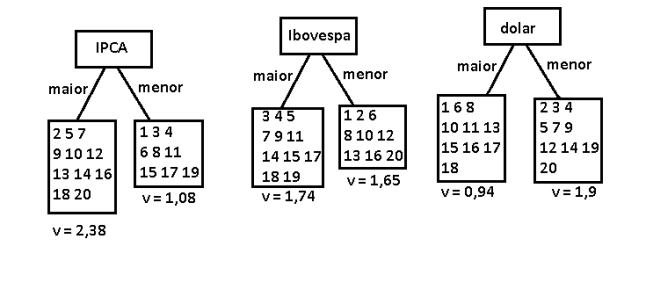
Depois de algumas tentativas descobri que um jeito interessante de captar os melhores padrões é separar os dados pela média. Colocar de um lado os que são maiores e de outro os que são menores que a média e fazemos isso para cada coluna.
Depois disso medimos a variância da Label de cada subconjunto e selecionamos aquele com menor variância para ser o novo ramo. Depois refazemos o processo para cada subconjunto.
Existem muitas formas modernas de se construir uma DT para regressões algumas mais simples e outras bem mais complexas optei por fazer dessa forma pela simplicidade com que o processo é feito.
Antes de começar vamos definir as técnicas que usaremos.
A boa e velha media é representada pela seguinte fórmula:
Onde é o número de elemento do vetor, no nosso caso serão as colunas, eé o valor do elemento.
A variância é representada pela seguinte fórmula.
A variância para quem não sabe funciona como uma média da diferença dos valores em relação a média.
Primeiro passo:
Calcula-se a média de todos os atributos\colunas menos a ultima pois essa é o alvo da predição.
media(Ipca) = 0.10
media(Ibovespa) = -0,12
média(Dolar) = 0.15
Depois disso separamos as instâncias. Vamos colocar as que são menores ou iguais a média de um lado e as que são maiores em outro. Fazemos isso para cada atributo.
E claro calculamos a variância label Ação para cada conjunto
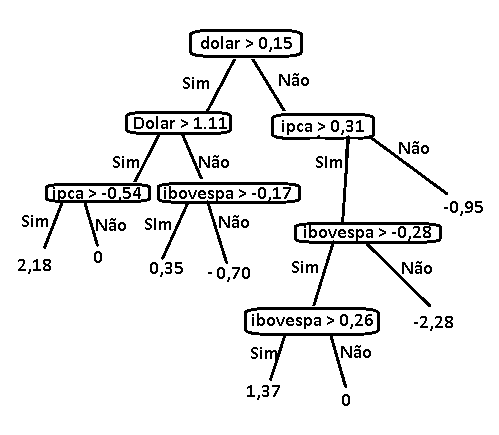
Isso feito teremos o seguinte esquema.
Isso feito pegamos o atributo que melhor divide o Dataset em dois, repare que isso é uma forma de captar uma correlação entre o valor do atributo e o preço. A ideia é dividir em grupos cada vez mais semelhantes onde a variância na variação do preço da ação seja cada vez menor.
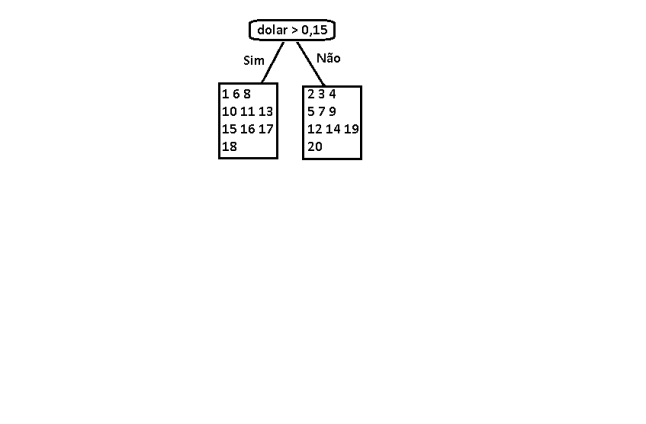
Escolhemos o Dolar pois um de seus subconjuntos tem a menor variância isso quer dizer que as instâncias são menos dispersas ali.
Repare que agora temos o nosso primeiro discriminante
Com isso feito repetimos o processo para cada ramo. Tiramos a média e separamos os maiores de um lado e os menores de outro, fazemos isso para cada atributo e selecionamos aquele que melhor divide o conjunto.
Para fins didáticos usareis como folha o Node que tiver 3 ou menos amostras, pois se fazer o processo indefinidamente pode levar a árvore a overfitting. Apesar de não ser o melhor jeito a definição do número de elementos mínimos para ser uma folha é muito usado para evitar overfitting.
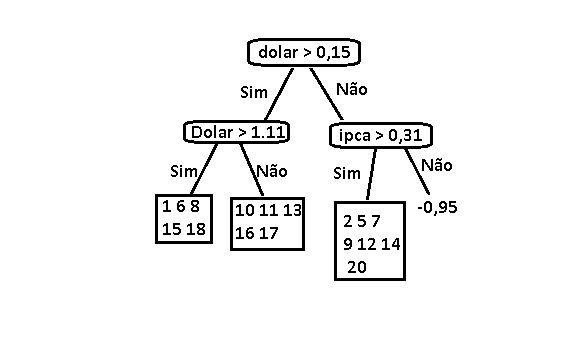
Se repetimos o processo teremos a seguinte estrutura:
Vamos repetir o processo mais uma vez agora para cada um dos 3 subconjuntos formados.
Repare que agora temos uma folha na árvore, isso aconteceu pois a quantidade de amostras naquele ramo chegou em 3, então usei a média dos preços das ações que compunham essa amostra como output.
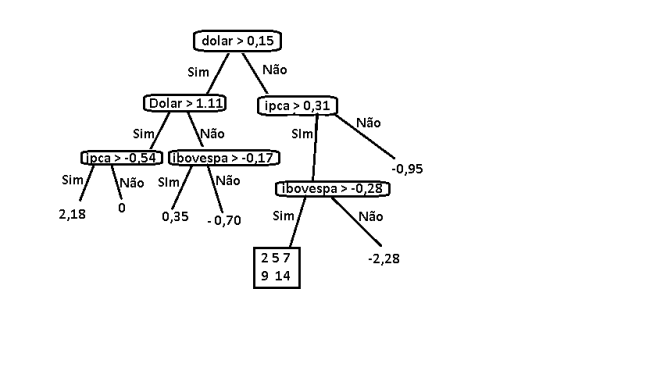
Vamos realizar mais uma iteração para ver como fica a estrutura.
Repare que ainda faltam 5 instâncias para usarmos para treino vamos repetir o processo. Depois de feito teremos a seguinte estrutura.
Você pode testar no conjunto de teste. Infelizmente ela não tem um desempenho tão bom pois usamos poucos dados para treino mesmo assim o resultado é interessante.
O Erro médio absoluto fica em torno de 0,312.
Confesso ser muito bom apesar do método usado e da quantidade de dados.
Então é isso esse foi o post de hoje.
Ola pessoas que leem meu blog. O post de hoje ainda é sobre Decision Trees. Esse post é de certa forma uma continuação do Decision tree com sklearn naquele eu usei o framework Scikit-learn para fazer uma Decision-tree para classificação.
O código que será usado como base do post se encontra no final, caso prefira já ir pegando e acompanhando o post com ele pronto, assim também você pode ir vendo quais módulos faltam.
No post de hoje usaremos Decision tree para fazer regressões. Para quem não estar acostumado com essa ideia deve estar pensando: Isso é possível? DT não é um algoritmo para classificação? As resposta para as duas perguntas são: Sim é possível e o modelo não é apenas uma algoritmo para classificação apesar da versão ID3 originalmente ser criado para classificação surgiu depois a versão C4.5 que é uma versão otimizado do anterior e que nos permite com os ajustes necessários aplicar ele em um problema de regressão.
Mas antes de continuar vamos definir o que é regressão em Machine learning:
Em machine learning é considerado uma a regressão simples a tarefa de se associar um valor continuo a um vetor contendo variáveis independentes. Temos outras definições na Estatistica para esse termo porem aqui será o simples ato de gerar uma transformada que leva um vetor e retorna um valor real qualquer.
Isso dito vamos ao problema de hoje:
O problema, bem simples, consiste em estimaro número de interação esperada em um post do Facebook com base em alguns valores de variáveis, você pode conseguir o DataSet aqui.
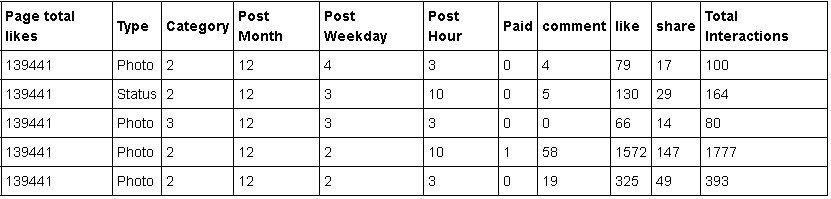
Infelizmente não mostrarei a tabela toda aqui hoje pois é bem grande, temos 18 atributos/colunas mas você pode abrir em seu computador e dar uma olhada por você mesmo.
Não usarei todos os atributos para treinar o modelo existem alguns que são muito específicos do Facebook mas irei falar daqueles que usarei e um pouco do porque.
Vamos ao nossos atributos:
Page total likes: Trata-se da quantidade de curtidas que a página que fez o post possui, os valores são discretos. Porem podemos facialmente definilos como continuos dependendo do contexto pois não existe um limite definido para o número de likes.
Type: É o tipo de mídia. É uma variável qualitativa nominal, já que não apresenta ordenação, e temos quatro tipos; Photo, Status, Link e Vídeo é uma variável bem interessante.
Category: É uma variável discreta com valores de 1 a 3, não soube interpretar se é quantitativa ou qualitativa, acredite pesquisei mas parece haver uma correlação interessante com a variável dependente.
Post Month: Esse é o mês em que o post foi postado é uma variável qualitativa ordinal pois separa os posts em mêses do ano. Variáveis assim são extremamente uteis para captar sazonalidade nos dados.
Post Weekday: A semana do mês. Um variável qualitativa ordinal que quando combinada com a Post Month nos fornece bastante informação sobre sazonalidade.
Post Hour: Podemos dizer que é de certa forma uma variável qualitativa ordinal já que ordena as horas e minutos de um dia em determinadas partes bem definidas. Nos fornece ainda mais detalhes sobre sazonalidade.
Paid: Variavel qualitativa nominal. Aqui sabemos se a publicação é paga ou não. 1 para Sim e 0 para Não.
Comment: Número de comentários na publicação. Uma variável quantitativo discreta.
Like: Número de likes na publicação. Uma variável quantitativa discreta.
Share: Número de compartilhamentos do post. Quantitativa discreta.
Total interactions(variável dependente.): Aqui vemos o número total de interações que o post teve essa é a classe que iremos regredir.
Depois de escolhido os atributos teremos uma tabela similar a essa:
Agora prepare seu editor que vamos arquitetar nosso modelo.
Primeiramente vamos importar as libes que serão usadas.
import pandas as pd #Analise e processamento de dados
from sklearn.preprocessing import LabelEncoder #Para transformar tipos de dados
from sklearn.tree import DecisionTreeRegressor #O algoritmo DT para regressão
from sklearn.cross_validation import train_test_split #Preparar o dataset para treino e teste
import matplotlib.pyplot as plt #Fazer alguns graficos
Isso feito vamos abrir nosso Dataset usando pandas.
#Vamos começar abrindo o documento
#Usarei pandas uma lib magnifica para analise e
#preparação de dados.
#Sempre olhar o tipo de separador na hora de abrir o documento.
data = pd.read_csv("dataset_Facebook.csv",sep=";")
Agora armazenarei o nome das colunas em uma variável. Isso facilita nosso trabalho na hora de nos referimos a um atributo especifico. Uma vez que os dados são carregado o Pandas os armazenas em um objeto chamado DataFrame, no nosso caso ele é exatamente igual a uma tabela. Quando uso .columns ele retorna os nomes de cada coluna.
#vamos colocar os nomes dos atributos em uma coluna separada
#isso é muito util para relaizarmos alguns procedimentos.
#É util para procurar valores faltando por exemplo
ft = data.columns
Agora na variável ft temos um objeto Index do Pandas que nada mais é do que uma lista contendo o nome de cada atributo. Isso facilita nossa vida na hora de selecionar uma ou múltiplas colunas.
In [1]: ft
Out[1]:
Index([u'Page total likes', u'Type', u'Category', u'Post Month',
u'Post Weekday', u'Post Hour', u'Paid', u'Lifetime Post Total Reach',
u'Lifetime Post Total Impressions', u'Lifetime Engaged Users',
u'Lifetime Post Consumers', u'Lifetime Post Consumptions',
u'Lifetime Post Impressions by people who have liked your Page',
u'Lifetime Post reach by people who like your Page',
u'Lifetime People who have liked your Page and engaged with your post',
u'comment', u'like', u'share', u'Total Interactions'],
dtype='object')
Uma boa oportunidade para usar a variável ft é para eliminar as colunas que não serão usadas para treinar o modelo. O método .drop() do pandas elimina uma ou várias colunas ou indices do DataFrame.
A seguir a usamos para retirar aquelas colunas que não iremo utilizar. Eu aconselho fortemente que você olhe e conheça bem o csv pois assim terá uma ideia de porque fiz isso nesse momento.
#Antes de usar o conjunto de dados serão eliminados alguns
#Atributos que não usarei para treino.
#axis=1 quer dizer que será as colunas
#Elimino as colunas que vão da posição 7 a 14 na variável ft.
data = data.drop(ft[7:15],axis=1)
Agora redefino a variável ft para incluir somente os nomes das colunas que restaram.
#Agora irei redefinir a variavel ft para incluir apenas
#os atributos que iremos usar
ft = data.columns
A partir de agora serão tratados os dados. Primeiro iremos reiscalar os valores da primeira coluna do DataFrame. Iremos coloca-los no intervalo -1 a 1.
Usaremos a seguinte fórmula:
valor atual = (antigo valor – valor mínimo)/(valor máximo – valor mínimo)
Usaremos o método .apply() do Pandas: Ele aplica uma função a todos os elementos de um vetor no caso a todos os valores da coluna Page total likes.
#Irei normalizar os dados da coluna page total likes.
#Apesar de não ser necessário para Dt isso nos ajuda diminuir
#o peso desse atributo e lidar com valores entre 0 e 1 é bem melhor para plotar
#Fazer um demonstração da função .apply
#Mas antes vamos definir algumas variaveis para ficar mais didaticos
maxi = data[ft[0]].max()
mini = data[ft[0]].min()
data[ft[0]] = data[ft[0]].apply(lambda x:(float(x) - mini)/(maxi-mini))
Agora trataremos os dados faltantes. Tarefa muito comum na hora de preparar o Dataset.
Usaremos o método .fillna que é exatamente para esse tipo de tarefa. Ele localiza todos os NA na coluna ou Dataframe, isso nos permite trocá-los por outros valores.
#Agora vamos cuidar dos valores faltando na coluna Paid
#Serão substituídos pela média
data[ft[6]] = data[ft[6]].fillna(data[ft[6]].median())
#Irei substituir os valores vazios na coluna like pela media
#Existem métodos mais apropriados
data[ft[8]] = data[ft[8]].fillna(data[ft[8]].mean())
#Irei substituir os valores da coluna Share pela média
data[ft[9]] = data[ft[9]].fillna(data[ft[9]].median())
Agora que temos os dados preparados vamos fazer alguns plots para ter uma ideia básica da distribuição dos dados.
Os plots são um pouco obvios mas usarei a oportunidade para mostrar algumas funcionalidades do Pandas.
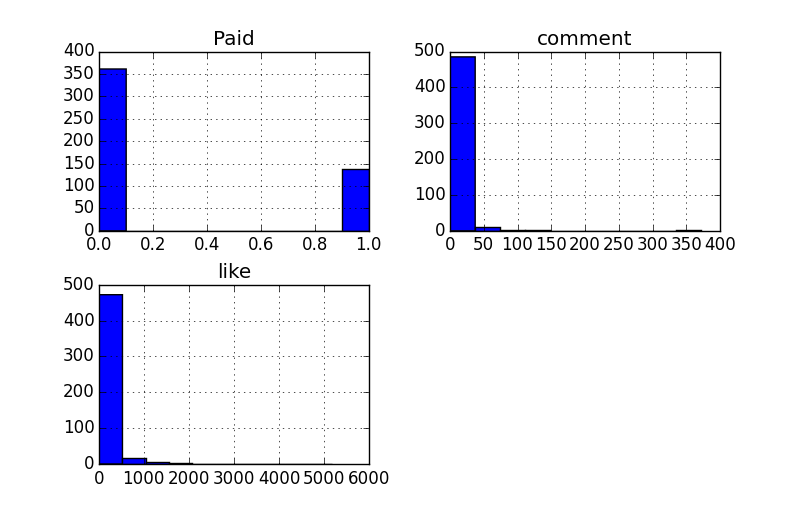
Usarei o método .hist() para fazer um histograma de Likes, Paid e Comment. veja abaixo.
Primeiro selecionamos as colunas com a qual queremos fazer o histograma.
In[ 1]: data[ft[6:9]].hist()
Olhar a figura acima nos fornece algumas informações relevantes, como por exemplo: a maioria das publicações não são pagas. A grande maioria das publicações tem menos de 50 comentários e uma grande maioria das publicações tem menos de 1000 curtidas. Esse tipo de análise é importante para identificar ruidos e viés nos dados.
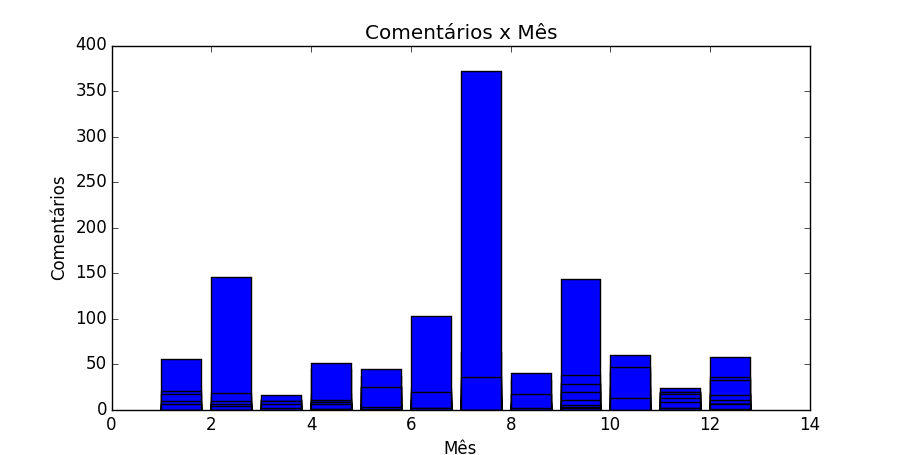
Podemos também plotar a quantidade de comments em relação aos meses do ano. Para saber em qual mês a publicação recebe mais comentários.
In[2]: plt.bar(data[ft[3]],data[ft[7]])
Quando olhamos no gráfico acima fica claro que o mês em que temos mais curtidas é entre julho e agosto. Pode ser interessante estudar porque isso acontece.
Poderíamos fazer muito mais plots e analises exploratórias. Mas vamos manter as coisas simples a intenção é aproveitar o post e mostrar algumas das funcionalidades do Pandas.
Agora que já preparamos e “estudamos” os nossos dados é hora de prepará-los para o modelo.
Primeiramente transformo todos os valores representados por Strings em dados numéricos usando a classe Label Encoder que já foi explicada no post Decision trees com sklearn parte 1
#Agora iremos passar a coluna Type para valores discretos.
#Usaremos a classe LabelEncoder()
le = LabelEncoder()
data[ft[1]] = le.fit_transform(data[ft[1]])
Vamos dividir nossos conjuntos de dados para treino e teste:
#Agora iremor separarar conjunto de treino e teste
x_train,x_test,y_train,y_test = train_test_split(data[ft[:-1]].values,
data[ft[-1]].values,
train_size=0.85)
Repare que selecionei as colunas e depois usei o atributo .value fiz isso pois o Scikit-learn pede arrays do NumPy como parametro e as colunas do DataFrame do Pandas é um objeto Series.
Agora vamos treinar nosso algoritmo.
#Repare que o criterio de separação é a média.
#No proximo post já irei esplicar essa ideia de manéira mais fundamentada.
regr = DecisionTreeRegressor(criterion='mae')
regr.fit(x_train,y_train)
Agora iremos medir nosso erro usando a função mean_absolute_error que nada mais é do que a soma das diferenças entre a predição e valor real divida pelo tamanho do conjunto de teste.
#Antes de rodar no Ipython criar uma função que armazena as predições
y = regr.predict(x_test)
In [1]: loss = mean_absolute_error
In [2]: loss(y_test,y)
Out[2]: 17. 800000000000001
Isso feito temos um algoritmo treinado e pronto para ser usado, Claro que temos que definir alguns parâmetros pois a taxa de erro esta relativamente alta.
Irei estabelecer uma variável para armazenar as predições do algoritmo e vamos fazer alguns plots para entender melhor a ideia de regressão e regular alguns parâmetros para manter o post mais curto irei começar a ajustar apenas a profundidade.
y = regr.predict(x_test)
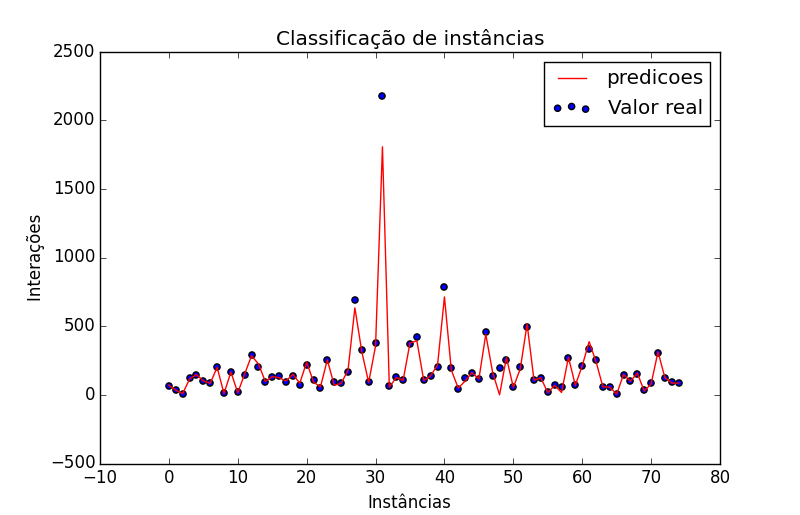
O grafico acima é para se ter uma ideia de como o modelo consegue desenhar uma linha entre o valor real das instâncias. O gráfico acima é mais ilustrativo do que explicativo pois no da uma ideia de como o modelo consegue se aproximar do valor real das istâncias.
Temos um algoritmo sem profundidade definida ou sejá ele cria novos Nodes ate quando não tiver mais, ou não ter a quantidade minima de amostras para criar um novo Node.
Isso faz com que tenda a overfitting . Vamos definir algumas profundidades para o gráfico e aproveitar para ver como ficaria em outras profundidades.
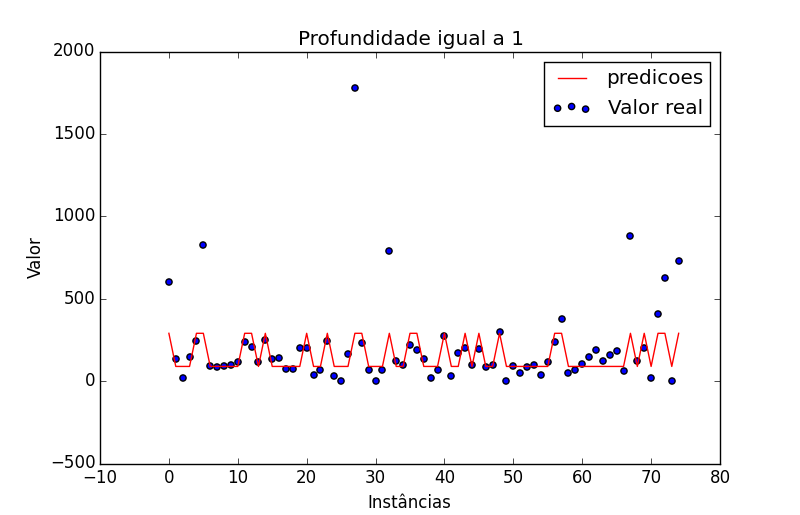
Irei mostrar como ficaria o grafico de uma arvore extremamente rasa com apenas um Node ou seja max_depth igual 1.
Repare em como ela desenha uma curva mais descompromissada na hora de predizer os valores. A taxa de erro dessa arvore é bem alta. É um exemplo muito bom de underfitting.
Irei deixar para você leitor testar quais seriam as melhores profundidades para ela.
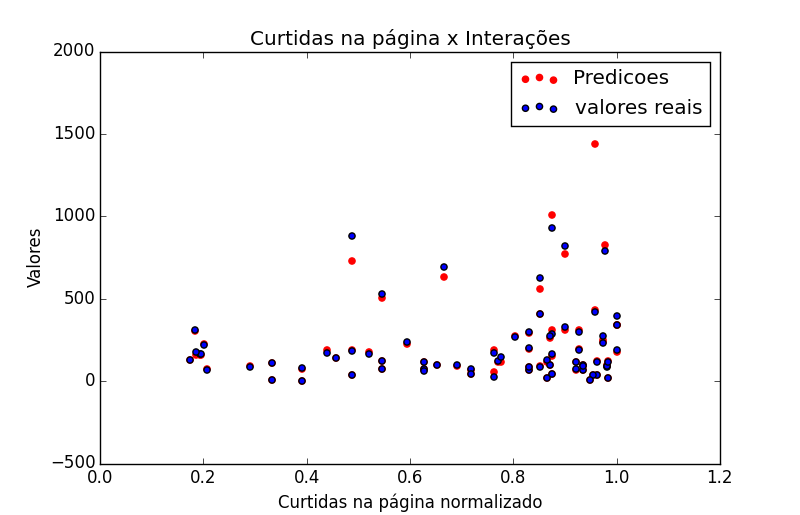
Outra maneira interessante de ver a arvore é fazendo um ScatterPlot. A seguir faço um plot com a profundidade igual a 10 o que reduz a taxa de erro consideravelmente.
Muito Bem galera esse foi post dessa semana espero que tenha sido util e possa te ajudar em seus estudos.
Caso tenha se interessado e queira se aprofundar no assunto não posso deixar de indicar o curso Machine Learning e Data Science com Python que é bem pratico e possui um excelente preço.
Segue o Código que foi usado como base.
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 20 16:44:11 2017
@author: julio
"""
import pandas as pd #Analise e processamento de dados
from sklearn.preprocessing import LabelEncoder #Para transformar tipos de dados
from sklearn.tree import DecisionTreeRegressor #O algoritmo DT para regressão
from sklearn.cross_validation import train_test_split #Preparar o dataset para treino e teste
import matplotlib.pyplot as plt #Fazer alguns graficos
from sklearn.metrics import mean_absolute_error
#Vamos começar abrindo o documento
#Usarei pandas uma lib magnifica para analise e
#preparação de dados.
#Sempre olhar o tipo de separador na hora de abrir o documento.
data = pd.read_csv("dataset_Facebook.csv",sep=";")
#vamos colocar os nomes dos atributos em uma coluna separada
#isso é muito util para relaizarmos alguns procedimentos.
#O pandas tem uma função chamada hasnans()
#É util para procurar valores faltando
ft = data.columns
#Antes de usar o conjunto de dados irei eliminar alguns
#Atributos que não irei usar para treino.
data = data.drop(ft[7:15],axis=1)
#Agora irei redefinir a variavel ft para incluir apenas
#os atributos que iremos usar
ft = data.columns
#Irei normalizar os dados da coluna page total likes.
#Apesar de não ser necessário para Dt isso nos ajuda diminuir
#o peso desse atributo e lidar com valores entre 0 e 1 é bem melhor para plotar
#Fazer um demonstração da função .apply
#Mas antes vamos definir algumas variaveis para ficar mais didaticos
maxi = data[ft[0]].max()
mini = data[ft[0]].min()
data[ft[0]] = data[ft[0]].apply(lambda x:(float(x) - mini)/(maxi-mini))
#Agora vamos cuidar dos valores faltando na coluna Paid
data[ft[6]] = data[ft[6]].fillna(data[ft[6]].median())
#Irei substituir os valores vazios na coluna like pela media
#Existem métodos mais apropriados
data[ft[8]] = data[ft[8]].fillna(data[ft[8]].mean())
#Irei substituir os valores da coluna Share pela média
data[ft[9]] = data[ft[9]].fillna(data[ft[9]].median())
#Agora iremos passar a coluna Type para valores discretos.
#Usaremos a classe LabelEncoder()
le = LabelEncoder()
data[ft[1]] = le.fit_transform(data[ft[1]])
#Agora iremor separarar conjunto de treino e teste
x_train,x_test,y_train,y_test = train_test_split(data[ft[:-1]].values,
data[ft[-1]].values,
train_size=0.85)
regr = DecisionTreeRegressor(criterion='mae')
regr.fit(x_train,y_train)
y = regr.predict(x_test)
plt.scatter(x_test[:,0],y,color="red")
plt.scatter(x_test[:,0],y_test)
plt.legend(['Predicoes','valores reais'])
plt.plot(range(len(y)),y,color="red")
plt.scatter(range(len(y)),y_test)
plt.legend(["predicoes","Valor real"])
loss = mean_absolute_error
loss(y_test,y)



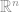 para
para 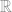 . Espero que tenha ficado minimamente claro a tarefa de hoje, caso não, continue lendo o post que as coisas darão uma clareada.
. Espero que tenha ficado minimamente claro a tarefa de hoje, caso não, continue lendo o post que as coisas darão uma clareada.


 é o número de elemento do vetor, no nosso caso serão as colunas, e
é o número de elemento do vetor, no nosso caso serão as colunas, e