Olá meus queridos sete leitores!
Para você que vem estudando Machine Learning ou se deparou com esse tópico na faculdade já deve ter encontrado em seu caminho um modelo chamado perceptron multicamadas do inglês Multilayer perceptron.
Para aqueles que querem se aprofundar nos estudos de redes neurais artificiais e nas aplicações desses modelos matemáticos fascinantes é de extrema importância entender a topologia dessa rede e um pouco algoritmo utilizado para a otimização.
No post de hoje iremos fazer um tutorial simples desse modelo e do algoritmo gradiente descendente que pode ser usado para treiná-lo. Aqui irei focar na simplicidade e mostrar a forma mais básica desse modelo. É importante lembrar que existe uma enorme quantidade cálculos envolvidas no processo, porem são cálculos simples que podem ser aprendido se forem estudados com calma de forma separada. Convido a você dar uma olhada nesse post como um ponta pé inicial para se aprofundar em deep learning. A ideia de MLP vai nos da uma generalização, mesmo que simples nesse caso, do principal problema que estamos interessados em solucionar
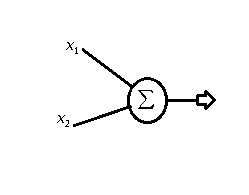
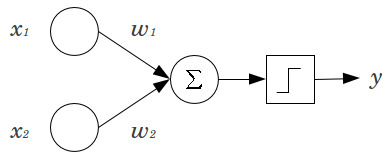
Antes de entrar de cabeça no post é interessante que você saiba como funciona o modelo Perceptron. Eu fiz um post sobre o assunto: Introdução ao perceptron passo a passo.
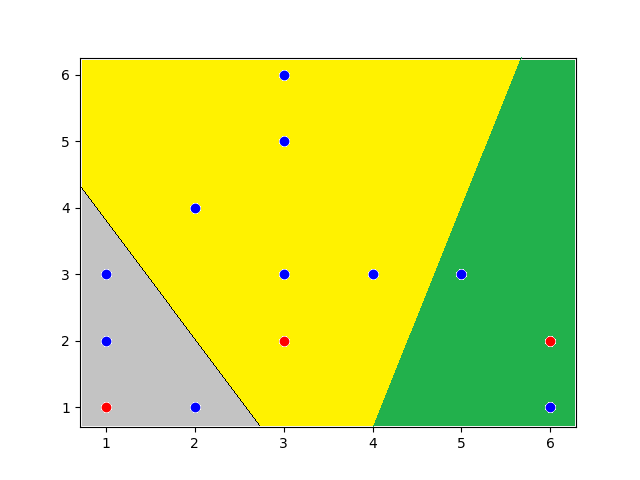
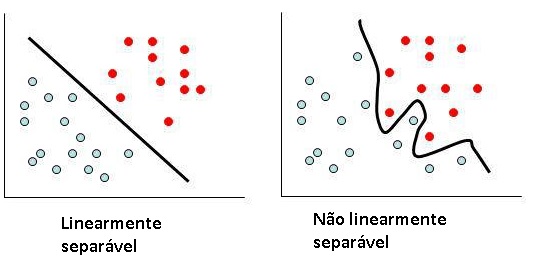
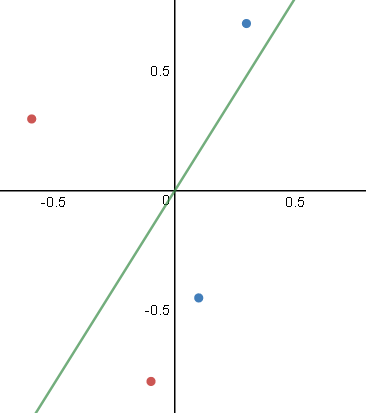
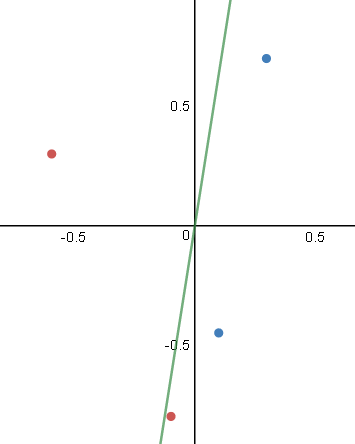
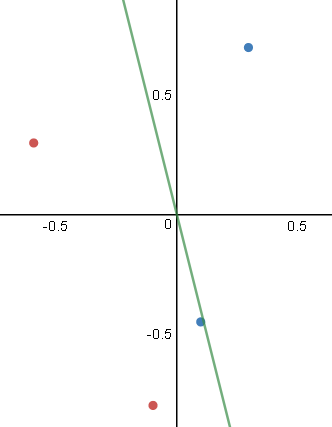
Para você que já entendeu como funciona o perceptron deve ter notado também sua limitação quando aplicado a problemas de classificação. Ele apenas resolve problemas em que os dados são linearmente separáveis. Ou seja, situações em que é possível traçar uma “reta” entre os dois conjuntos.
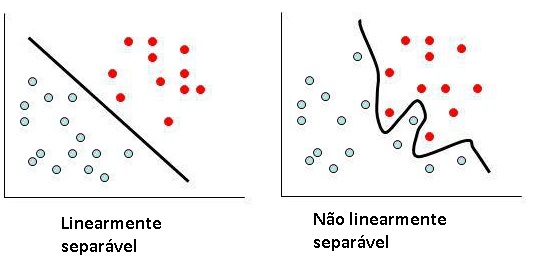
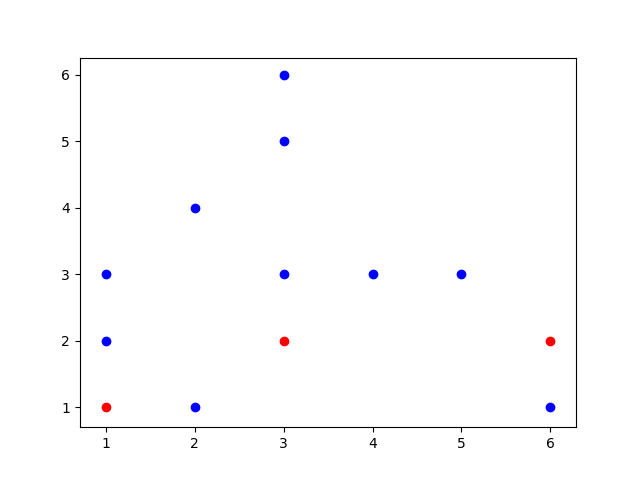
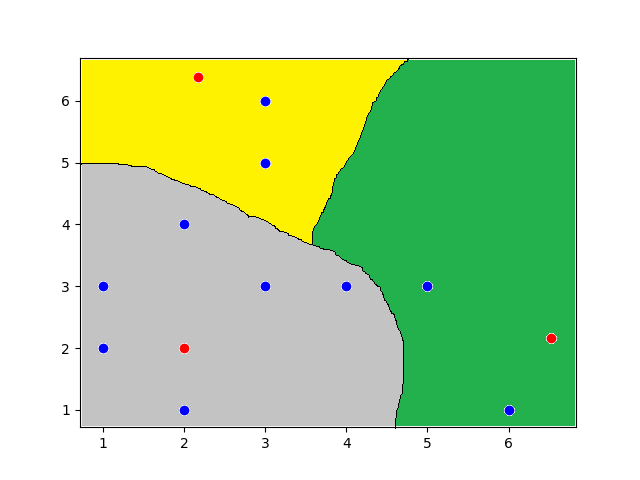
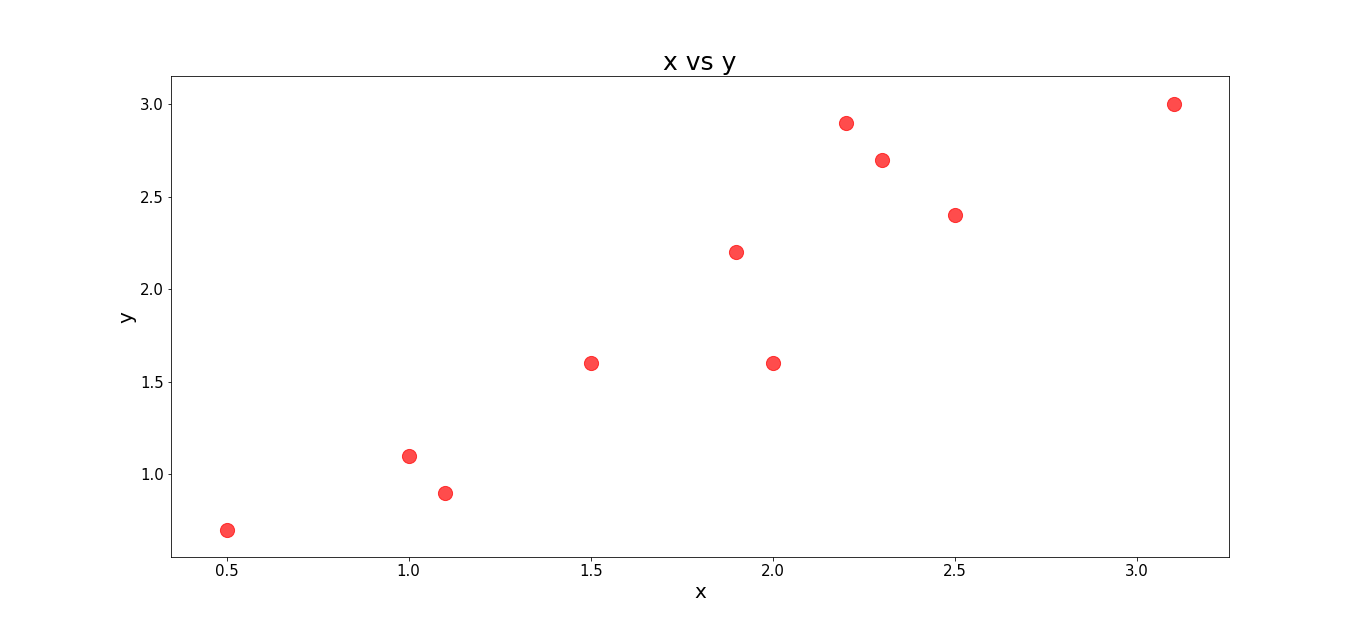
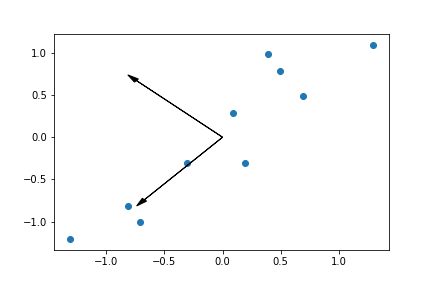
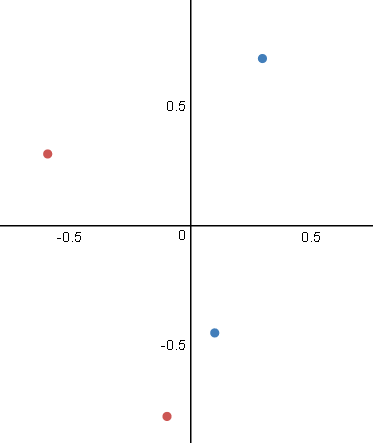
Hoje iremos focar no tipo de problema representado à direita.
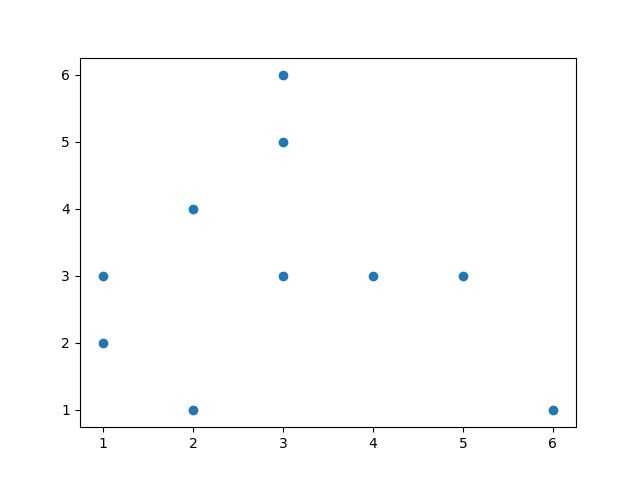
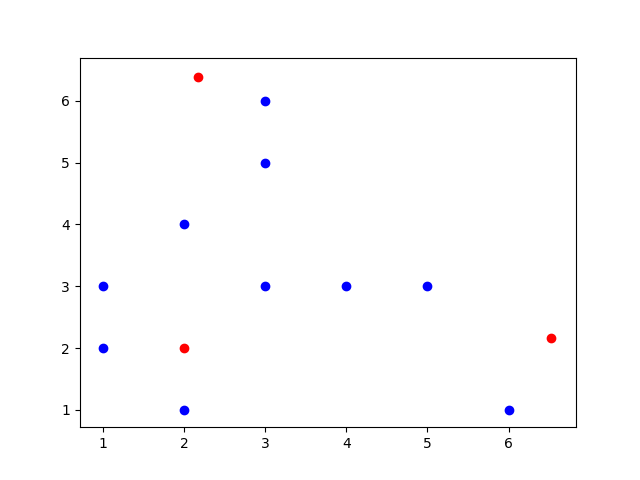
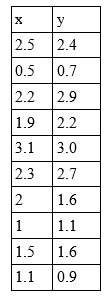
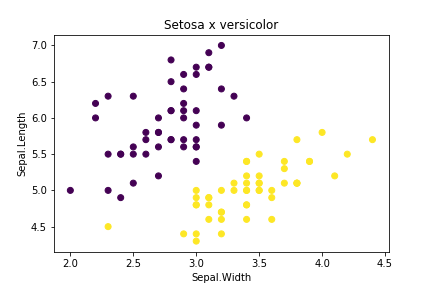
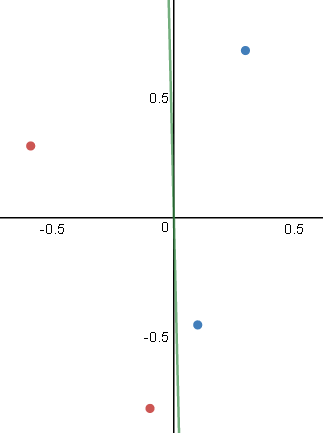
Para isso vamos usar um conjunto de dados fictício representado no gráfico abaixo:
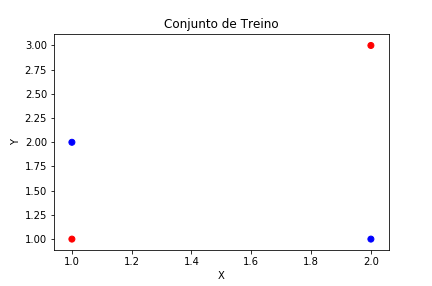
Repare que nessa situação é impossível traçar uma reta que divide os conjuntos em duas partes. Logo, não é possível resolver o problema utilizando um simples Perceptron.
Observação!! : A escala dos dados aqui estão entre 1 e 3. Ná prática é necessário reescalar seus dados pois o MLP é sensível a escala dos dados e isso pode gerar uma série de inconsistência numéricas, irei discorrer sobre isso em post futuros, mas para esse exemplo irei deixar dessa forma para facilitar um pouco mais os cálculos.
O modelo Perceptron multicamadas
Multilayer Perceptron, apesar do nome, não se refere a um perceptron com múltiplas camadas. Tecnicamente ele seria composto de vários perceptrons, mas só tecnicamente, pois pela definição o Perceptron é um tipo especial de rede neural que apenas realiza classificação binária.
No nosso caso é importante saber que graças a essa camada oculta (hidden layer) podemos captar novos padrões . É possível aprender funções polinomiais e não lineares em geral.
Segundo o teorema de George Cybenko um multilayer perceptron com uma função de ativação sigmoide é um aproximador universal para qualquer função de base real. Mas não irei entrar em detalhes sobre isso. O que nos interessa por hora é aprender o básico de como esse modelo é otmizado.
Definindo o modelo e os parâmetros
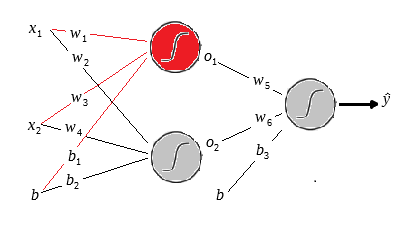
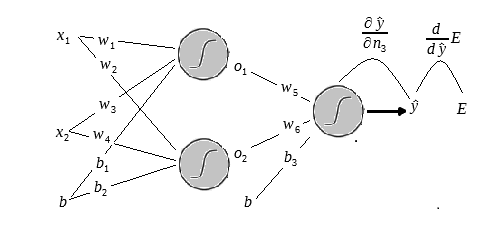
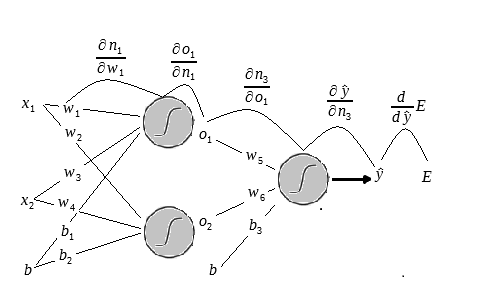
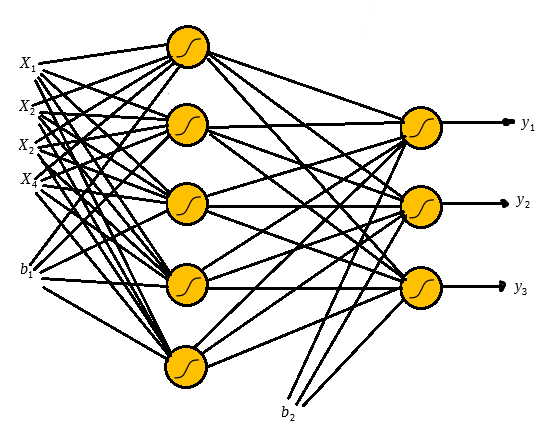
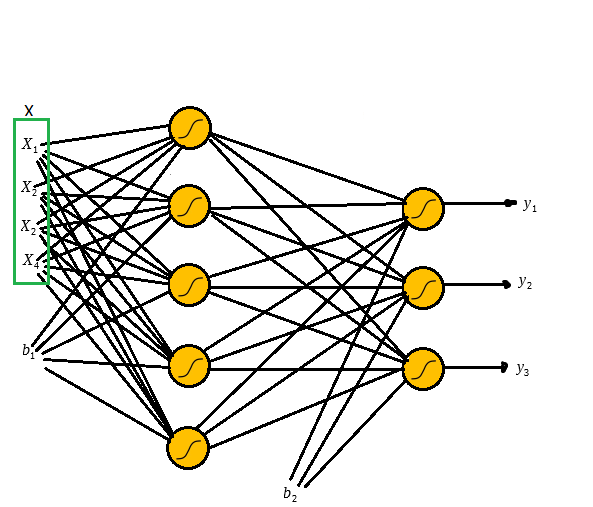
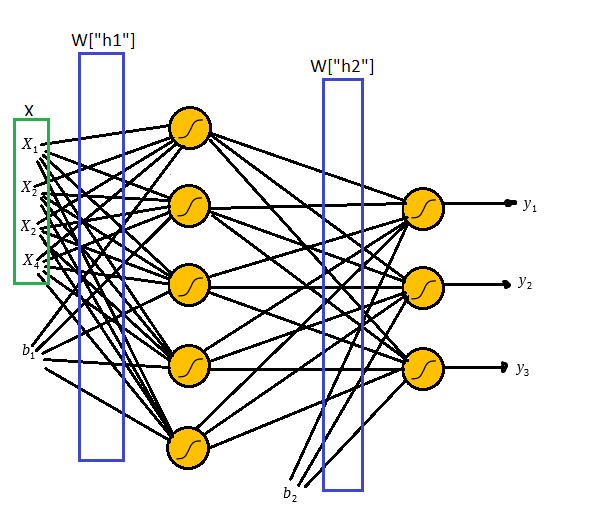
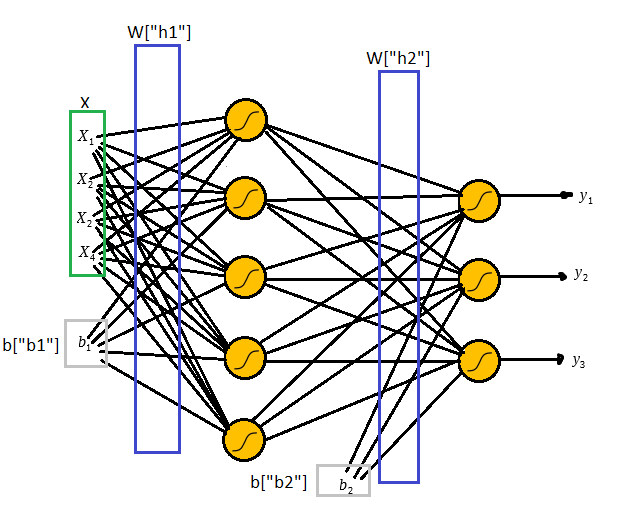
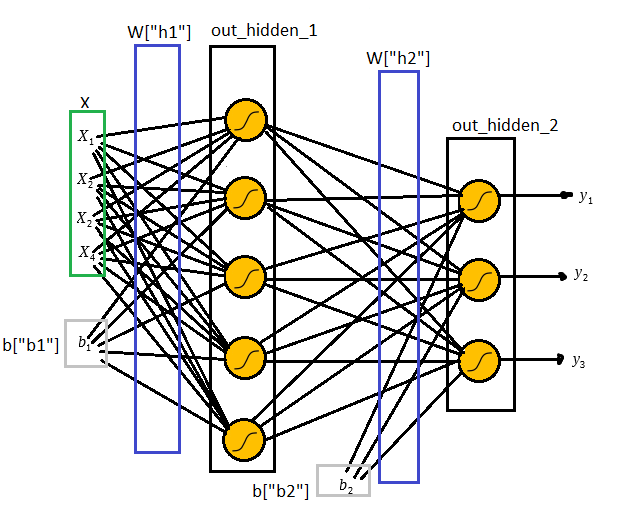
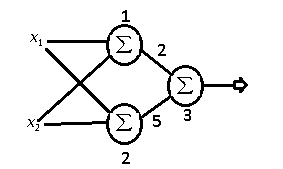
Para resolver esse problemas utilizaremos a seguinte a arquitetura:
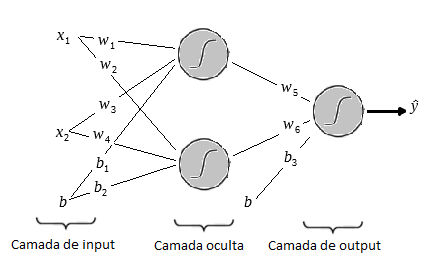
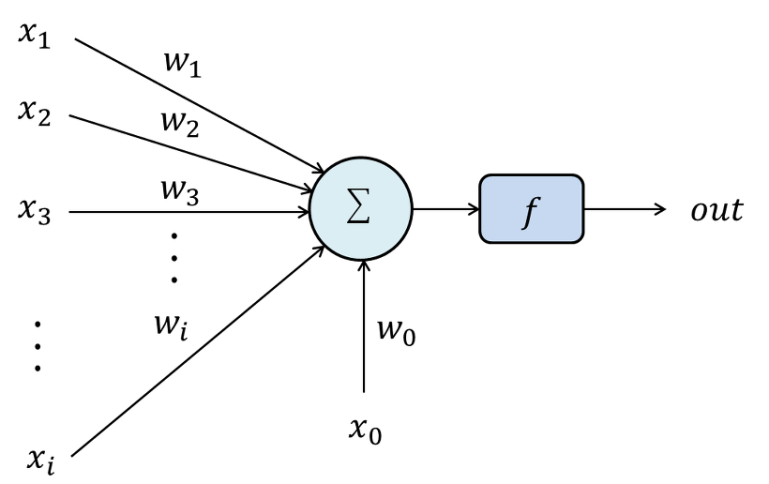
Na figura acima temos o layer de input com os dois inputs 


Uma observação sobre o bias é que ele sempre levara o input 1, o que importa de fato são os pesos 



Uma vez que multiplicamos os pesos e adicionamos os biases aplicamos a função sigmóide e o mesmo processo é feito nos outputs da primeira camada até gerar os outputs da rede.
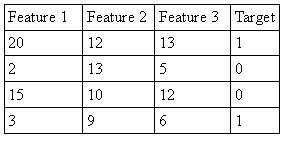
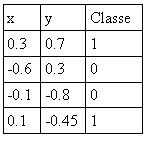
Organizamos o conjunto de treino em uma tabela que pode ser visualizada abaixo:
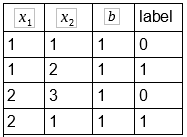
Repare que na coluna
Vamos agora definir nossos pesos iniciais de forma aleatória.






Definimos os biases:

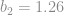

Agora definimos os parâmetros da rede e a função de ativação:
Aqui definimos o alpha, a taxa de aprendizado, esse parâmetro regula a velocidade com que a rede irá aprender. Usei um alpha menor pois vi que com valores maiores a rede pode simplesmente passar do ponto ótimo.
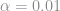
A seguir à função de ativação sigmóide que irá gerar o output de cada neurônio. A função sigmóide é interessante pois tende a 1 quando x tende ao infinito e tende a 0 quando x tende ao infinito negativo. Ela nos dá um discriminante em 0.5 acima disso posso classificar como positivo e abaixo como negativo por exemplo.

O 

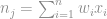
Aqueles da área de estatística podem estranhar a fórmula acima pois falta
Dessa forma multiplicamos todos os inputs e adicionamos ao somatório.
Nossa função de perda(Loss Function.) será o erro quadrático médio.

Aqui o erro 
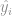

Temos que minimizar esse erro e assim achar o melhor conjunto de parâmetros 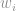

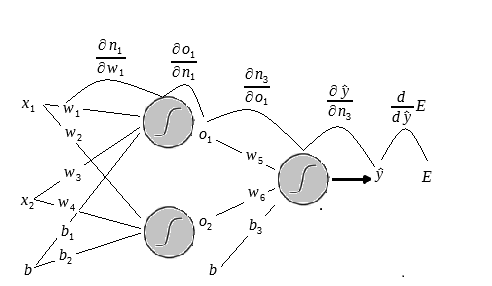
Antes de partir para o treino vamos tentar entender como é gerado o output final do MLP.
Entendendo como a informação é processada
Na figura abaixo iremos calcular o output do neurônio vermelho. Aqui e são os outputs dos dois neurônios das camadas ocultas respectivamente, depois de aplicar a função sigmoide.
Na figura temos o vetor de input que será é representado por:
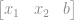
E repare que temos o vetor de peso, as arestas em vermelho que é representado por:

Multiplicaremos cada input pelo seu respectivo peso e somaremos o resultado. Isso nada mais é do que o produto entre dois vetores.
Vamos substituir o vetor de input pela terceira linha do conjunto de treino(Pois a primeira tem apenas 1 e pode ficar confuso) e o vetor de pesos pelos seus respectivos pesos e realizar a multiplicação.
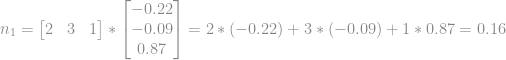
Esse é o resultado da multiplicação do input pelos pesos correspondente da camada, após isso vamos aplicar a função sigmoide e dessa forma gerar o output do neurônio em vermelho.

No estado atual esse seria o output do neurônio vermelho.
Fazemos o mesmo procedimento para obter o output do outro neurônio.

depois basta aplicar a sigmoid:
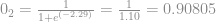
Dessa forma obtemos o output da primeira camada. Veja no desenho abaixo.
Olhe com atenção a mecânica dos cálculos, pois assim ficará mais fácil entender como é feito o treino da rede.
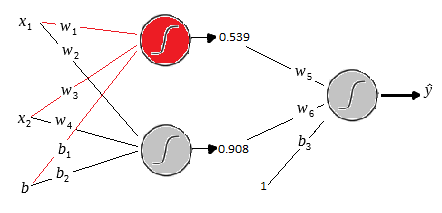
Vamos calcular o output final da rede. Repare que temos os pesos 

Agora basta substituir os valores:

Aplicamos a função sigmóide para gerar o output final da rede:
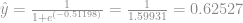
Esse é o output da rede para a terceira linha do nosso conjunto de treino. Se está certo ou errado depende da forma que decidir o discriminate.
É comum usarmos uma regra do tipo: Acima de 0.5 é igual a 1 e abaixo de 0.5 é igual a 0. Por essa regra a predição estaria errada e teríamos que otimizar a rede.

Treinando o Perceptron Multicamadas
A primeira coisa a fazer agora é calcular os outputs para todos os exemplos do conjunto de treino abaixo.
Como foi demonstrado acima a forma que o MLP processa a informação irei me abster de realizar os cálculos e já podemos demonstrar o resultado de cada output na coluna net_out.
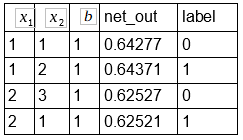
Com isso feito podemos medir o erro quadrado médio:

Logo basta somar os quadrados das diferenças dos outputs da rede em relação às labels e dividir pela quantidade de exemplos vezes 2. Lembrando que multiplicamos por 2 apenas para facilitar o cálculo da derivada.
Dê uma olhada no cálculo abaixo:
![E = \frac{1} { 2*4 } *[ (0.64277 - 0)^2 + (0.64371 - 1)^2+(0.62527 - 0)^2+(0.62521 - 1)^2] =](https://s0.wp.com/latex.php?latex=+E+%3D+%5Cfrac%7B1%7D+%7B+2%2A4+%7D+%2A%5B+%280.64277+-+0%29%5E2+%2B+%280.64371+-+1%29%5E2%2B%280.62527+-+0%29%5E2%2B%280.62521+-+1%29%5E2%5D+%3D+&bg=ffffff&fg=808080&s=0&c=20201002)

Aqui tivemos um erro quadrado médio de 0.13393.
Agora que sabemos o erro podemos iniciar a propagação do erro para as camadas e atualizar cada peso conforme a regra abaixo.

Onde 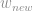



Mas antes voltemos ao esquema da rede.
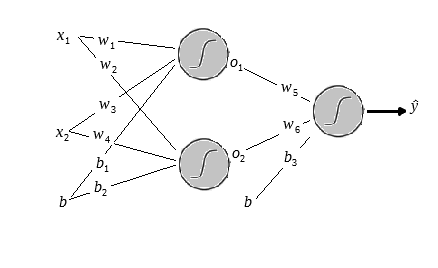
Repare que para atualizar um peso dessa rede teremos que achar o gradiente do erro em relação ao peso que iremos utualizar.
Iremos realizar a primeira atualização da rede passo a passo de forma bem simples.
A primeira coisa que temos que fazer é achar a derivada do erro total 
Logo:

A conclusão que chegamos aqui é que a derivada de 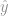
Antes de ir para o próximo passo observe o desenho a abaixo:
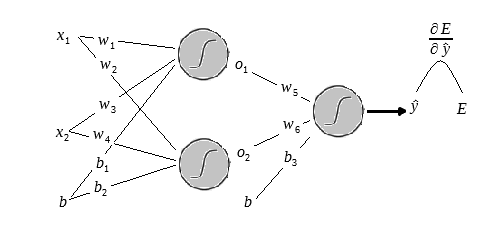
Acrescentei no final a letra
Agora iremos achar a derivada do output da rede em relação a 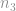


Não irei entrar no mérito de derivar a função sigmóide aqui. Dado que o post já está grande demais. Porém você pode dar uma olhada neste excelente post do portal Towards Data Science que mostra de maneira detalhada o processo de derivação dessa função:
https://towardsdatascience.com/derivative-of-the-sigmoid-function-536880cf918e
Assumimos que a derivada do ouput

Onde
Repare que 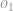
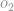


O próximo passo é a parcial do output
vamos atualizar
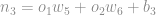
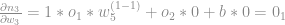
Observe a figura abaixo:
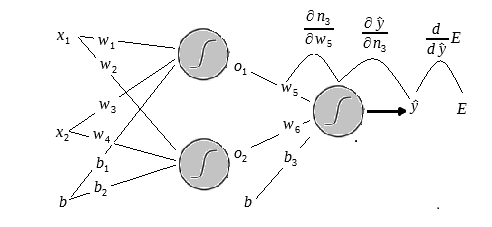
Aqui concluímos que a derivada parcial do resultado 
Porém o que interessa aqui é saber a derivada parcial do erro em relação a esse peso. Para isso basta utilizar a regra da cadeia.
Ou seja:
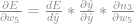
Uma observação importante: Irei utilizar a média dos valores dos gradientes dos outputs para atualizar o peso. Na fórmula acima temos a regra para atualizar com base em um único output, estocástica, porém iremos atualizar de forma direta, utilizando todo o conjunto de treino.
Vamos começar vendo a derivada do erro atual
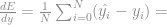
![= \frac{1}{4}*[(0.64277 - 0) + (0.64371 - 1)+(0.62527 - 0)+(0.62521 - 1)] =](https://s0.wp.com/latex.php?latex=+%3D+%5Cfrac%7B1%7D%7B4%7D%2A%5B%280.64277+-+0%29+%2B+%280.64371+-+1%29%2B%280.62527+-+0%29%2B%280.62521+-+1%29%5D+%3D+&bg=ffffff&fg=808080&s=0&c=20201002)

O próximo passo é calcular o
É importante lembrar aqui que como estamos trabalhando com um batch o que teremos na verdade é a média dos gradientes de cada erro em relação ao peso em questão.
Vamos dar uma olhada nisso mais de perto. Como vimos a derivada da sigmoid é dada por:

O gradiente para o primeiro input seria:

Mas o que queremos é a média de todas as derivadas de um dado Batch. No nosso caso todo o conjunto de treino.
Logo teremos:

Agora basta achar a derivada do resultado
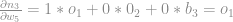
Como queremos a média de todos outputs do batch basta somar todas as saídas de
Logo teremos:
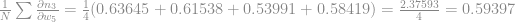
Agora pela regra da cadeia temos que:

Com isso temos o gradiente do erro em relação ao peso
Vamos antes lembrar alguns parâmetros da rede.
O primeiro é a taxa de aprendizado que foi definida em 0.01. O segundo é o peso
logo temos:
E agora basta aplicar a regra de atualização:

Com isso concluímos a atualização do primeiro peso da rede.
Temos agora:

Vamos fazer o mesmo procedimento para, abaixo temos o valor inicial do peso:
Lembrando que a derivada parcial de

Dae basta pegar a média dos gradientes de

Aplicamos a regra da cadeia:

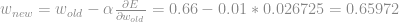
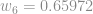
Se aplicarmos o mesmo procedimento ao bias 
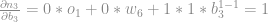
Aqui é importante lembrar que o input do bias é sempre 1. por esse motivo a derivada do bias é igual a 1. depois basta tirar a média de todas as derivadas dos inputs que compõem o conjunto de treino.

É interessante notar que a derivada do bias é 1 justamente por esse ser o coeficiente linear da equação que compõe o output.
E finalmente calculamos a derivada do erro em relação ao bias:
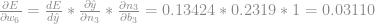
Com isso em mãos podemos atualizar o bias dessa camada:

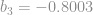
Até aqui já atualizamos a última camada da rede.
Porém agora atualizaremos os pesos da primeira camada. partiremos do peso
Antes precisamos entender como o erro varia em relação a esse peso.
Se olhar na figura anterior podera ver que derivamos o erro ate em relação a
Para calcular a variação do erro em relação a
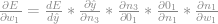
Repare que não derivamos o erro mais em relação a
Vamos começar o processo. Como vimos antes já possuímos os gradientes do erro até em relação a
Logo vamos adicioná las a fórmula:

Lembrando que os valores se referem a média das derivadas do batch todo. Vamos calcular a próxima parte dessa derivada:
Como vimos:

Logo:

A diferença dessa derivada em relação a que derivamos na outra vez é que aqui derivamos em relação a
Como sabemos que inicial é igual a 1.32 basta multiplicar por 4 e dividir por 4. É bem óbvio que o valor será o mesmo, porém é interessante ilustrar.

Agora vamos à próxima derivada.
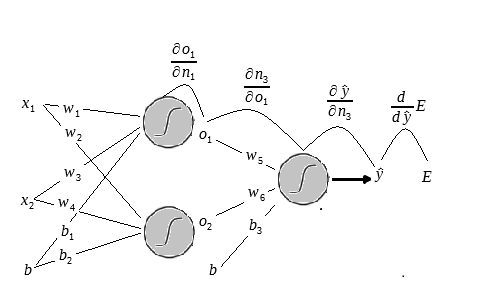
Sabemos que:
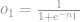
Logo:
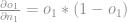
Agora pegamos a média dos gradientes para o batch:
![\frac{1}{4} \sum{\frac{\partial o_{1}}{\partial n_{1}}} = \frac{1}{4}[\sum{o_{ij}*(1-o_{ij})}] =](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B4%7D+%5Csum%7B%5Cfrac%7B%5Cpartial+o_%7B1%7D%7D%7B%5Cpartial+n_%7B1%7D%7D%7D+%3D+%5Cfrac%7B1%7D%7B4%7D%5B%5Csum%7Bo_%7Bij%7D%2A%281-o_%7Bij%7D%29%7D%5D+%3D+&bg=ffffff&fg=808080&s=0&c=20201002)
![= \frac{1}{4}[[0.63645<em>( 1 - 0.63645 ) + 0.61538 * (1 - 0.61538 ) + 0.53991</em>( 1 - 0.53991) + 0.58419*( 1 - 0.58419 )]]](https://s0.wp.com/latex.php?latex=+%3D+%5Cfrac%7B1%7D%7B4%7D%5B%5B0.63645%3Cem%3E%28+1+-+0.63645+%29+%2B+0.61538+%2A+%281+-+0.61538+%29+%2B+0.53991%3C%2Fem%3E%28+1+-+0.53991%29+%2B+0.58419%2A%28+1+-+0.58419+%29%5D%5D&bg=ffffff&fg=808080&s=0&c=20201002)
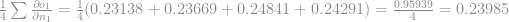
Agora basta encaixar esse resultado na equação:

O próximo passo é achar o gradiente de 
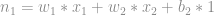
logo:
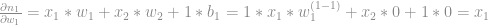
Calculamos a média de todos os inputs para
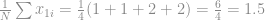
Encaixamos isso na equação para obter o resultado final, a variação do erro em relação ao peso

Com isso em mãos pode-se aplicar a regra de atualização. (Delta rule.) e atualizar o peso
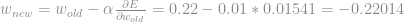
Irei aplicar o mesmo procedimento ao peso 
Como já temos a derivada parcial até o neurônio
Temos que:

Fazemos a atualização:


Vamos atualizar o bias
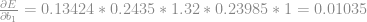
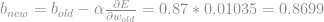

Com isso feito. Atualizamos os pesos que geram o output de primeiro neurônio da primeira camada oculta
Ainda falta fazer a atualização dos pesos
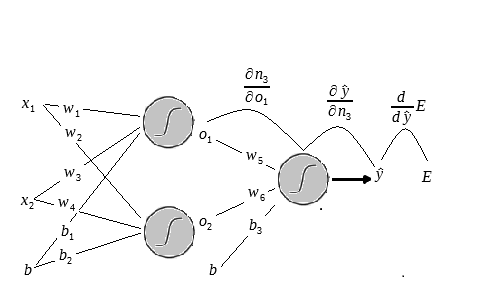
Veja a figura abaixo:
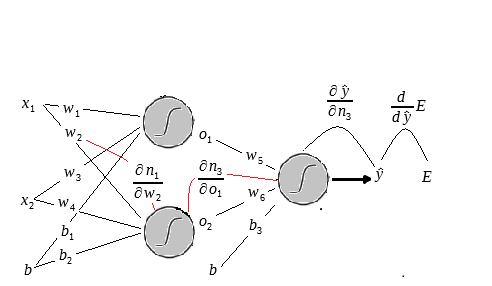
As linhas pretas indicam as derivadas que já possuímos e as vermelhas indicam as que devemos calcular agora.
Vamos iniciar calculando a derivada em relação a
Voltando a equação da cadeia com os gradientes que já possuímos vemos que:

Vamos calcular a próxima derivada:

Calculamos a média de para todos os elementos do batch que no caso é igual ao próprio

E encaixamos isso na nossa equação:

Agora é hora de achar a próxima derivada da equação.
sabemos que:
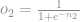
logo:
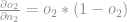
Agora basta pegar a média dos gradientes para o neurônio
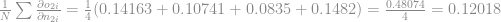
Encaixamos mais esse resultado em nosso equação:
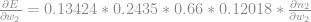
Agora iremos derivar a última parte. E como já vimos:


Agora basta adicionar a média dos quatro inputs em nossa equação:
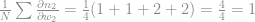

Com isso em mão podemos atualizar o peso


Como já sabemos que o processo é o mesmo para o peso
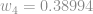

E com isso temos todos os pesos e biases atualizados e a primeira iteração terminada:

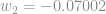
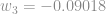

Agora vamos recalcular os outputs da rede e comparar os erros quadráticos médios:
Primeiro pegamos a tabela contendo todos os novos outputs da rede:
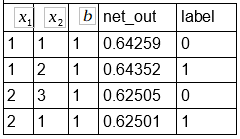
![E = \frac{1}{2*4} * [ (0.64259 - 0)^2 + (0.64352 - 1)^2+(0.62505 - 0)^2+(0.62501 - 1)^2] =](https://s0.wp.com/latex.php?latex=E+%3D+%5Cfrac%7B1%7D%7B2%2A4%7D+%2A+%5B+%280.64259+-+0%29%5E2+%2B+%280.64352+-+1%29%5E2%2B%280.62505+-+0%29%5E2%2B%280.62501+-+1%29%5E2%5D+%3D+&bg=ffffff&fg=808080&s=0&c=20201002)


O erro depois da atualização ficou em: 0.13390 houve pequena redução em relação a 1.3393.
Com isso encerramos a primeira época. Caso continuemos com o treino iremos repetir esse processo até minimizar o erro ao valor mínimo.
Repare que houve uma diminuição em todos os valores da rede. Isso ocorreu pois por hora todos os valores de outputs ainda estão acima de 0.5.
Para você que se interessou pelo post vale a pena tentar reproduzir o procedimento em uma linguagem de programação e analisar a convergência da rede.
Gostaria também de lembrar ao leitor que para fazer esse post foi necessário uma grande quantidade de cálculos manuais e então infelizmente existe uma probabilidade de erro e inconsistências e caso veja alguma coisa errada pode está entrando em contato com autor pois assim estará colaborando para o desenvolvimento de material de qualidade para a comunidade.
Até o próximo post e bons estudos.
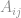 onde
onde 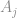 é o número de linhas e
é o número de linhas e 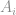 o número de classes e cada vetor
o número de classes e cada vetor 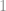 no índice da classe e
no índice da classe e  nos outros indices.
nos outros indices.

 e de y como
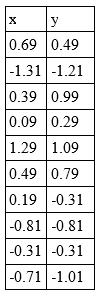
e de y como  e depois vamos subtrair esses valores de cada elemento da respectiva coluna.
e depois vamos subtrair esses valores de cada elemento da respectiva coluna.

 cresce a variável
cresce a variável 


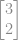 podemos considerar o primeiro elemento como
podemos considerar o primeiro elemento como 
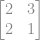 . iremos multiplicar essa matriz por aquele vetor, logo:
. iremos multiplicar essa matriz por aquele vetor, logo: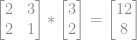
 no mesmo plano e ver o resultado:
no mesmo plano e ver o resultado: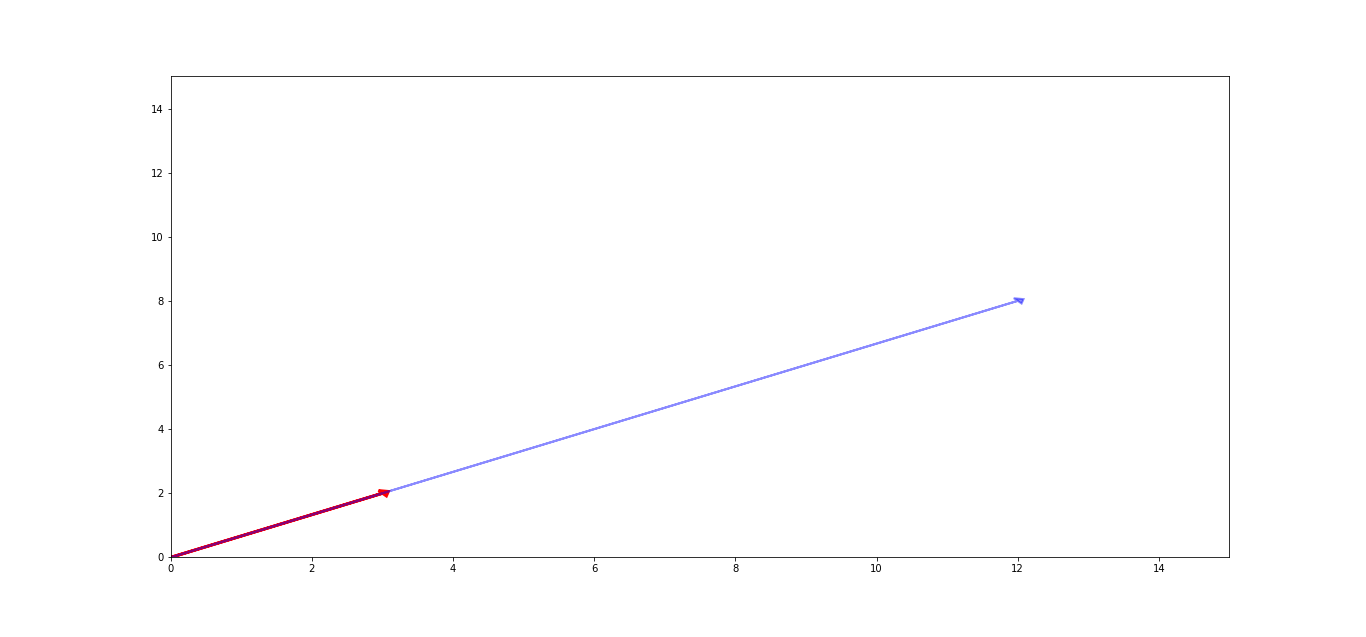
 .
. pela matriz
pela matriz  é o mesmo que multiplicar esse vetor por um escalar, que no nosso caso é 4.
é o mesmo que multiplicar esse vetor por um escalar, que no nosso caso é 4. seus autovalores
seus autovalores 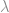 e seu autovetores
e seu autovetores  são respectivamente os escalares e vetores que satisfazem a seguinte equação:
são respectivamente os escalares e vetores que satisfazem a seguinte equação: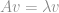

 e a matriz identidade de ordem n x n.
e a matriz identidade de ordem n x n.
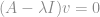
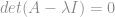
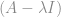 tem que ser uma matriz singular, não é inversível.
tem que ser uma matriz singular, não é inversível.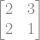 .
.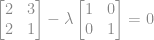

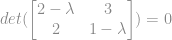

 e
e 
 .
.
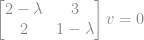
 e teremos que resolver o seguinte sistema:
e teremos que resolver o seguinte sistema: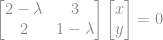


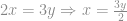

 temos:
temos:



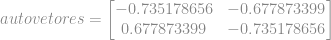

 é o resultado final,
é o resultado final,  é o vetor de componente principal selecionado e
é o vetor de componente principal selecionado e 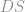 é nosso conjunto de dados ajustado. No nosso caso teremos que multiplicar a matriz que representa os dados pelo vetor ou matriz das componentes principais.
é nosso conjunto de dados ajustado. No nosso caso teremos que multiplicar a matriz que representa os dados pelo vetor ou matriz das componentes principais.  , basta lembrar do conceito de multiplicação de matrizes “linha vezes coluna”.
, basta lembrar do conceito de multiplicação de matrizes “linha vezes coluna”.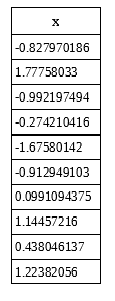

![\left [ x_{1},x_{2},x_{3},x_{4} \right ] * \begin{bmatrix} w_{1,1} &w_{1,2} &w_{1,3} &w_{1,4} & w_{1,5} \\ w_{2,1} &w_{2,2} &w_{2,3} &w_{2,4} &w_{2,5} \\ w_{3,1} &w_{3,2} &w_{3,3} &w_{3,4} &w_{3,5} \\ w_{4,1}&w_{4,2} &w_{4,3} &w_{4,4} &w_{4,5} \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cleft+%5B+x_%7B1%7D%2Cx_%7B2%7D%2Cx_%7B3%7D%2Cx_%7B4%7D+%5Cright+%5D+%2A+%5Cbegin%7Bbmatrix%7D+w_%7B1%2C1%7D+%26w_%7B1%2C2%7D+%26w_%7B1%2C3%7D+%26w_%7B1%2C4%7D+%26+w_%7B1%2C5%7D+%5C%5C+w_%7B2%2C1%7D+%26w_%7B2%2C2%7D+%26w_%7B2%2C3%7D+%26w_%7B2%2C4%7D+%26w_%7B2%2C5%7D+%5C%5C+w_%7B3%2C1%7D+%26w_%7B3%2C2%7D+%26w_%7B3%2C3%7D+%26w_%7B3%2C4%7D+%26w_%7B3%2C5%7D+%5C%5C+w_%7B4%2C1%7D%26w_%7B4%2C2%7D+%26w_%7B4%2C3%7D+%26w_%7B4%2C4%7D+%26w_%7B4%2C5%7D+%5Cend%7Bbmatrix%7D&bg=ffffff&fg=808080&s=0&c=20201002)
 ou
ou 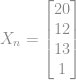

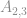 é 5.Ou seja o terceiro elemento da segunda linha.
é 5.Ou seja o terceiro elemento da segunda linha.



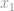 e
e 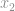 são os inputs e
são os inputs e 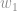 e
e  são os respectivos pesos de cada input.
são os respectivos pesos de cada input.

 é
é 




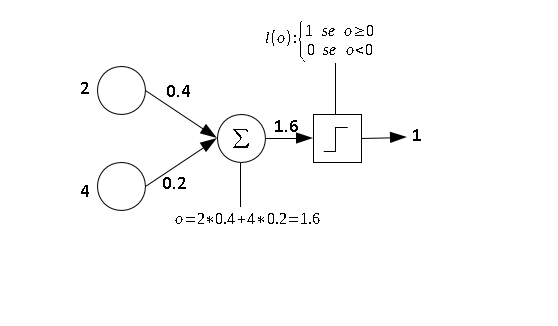


 e darei a ela o valor 0.5.
e darei a ela o valor 0.5.




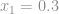
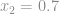


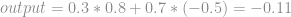

















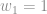










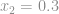
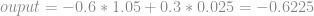

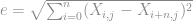

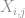 são linhas da matriz
são linhas da matriz 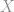 , enquanto que
, enquanto que 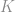 e
e  s
s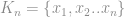 no qual a soma das distâncias entre eles e a instância
no qual a soma das distâncias entre eles e a instância  podemos extrair
podemos extrair  classes de elementos contidas no vetor, a partir daí basta aplicarmos o seguinte passo.
classes de elementos contidas no vetor, a partir daí basta aplicarmos o seguinte passo.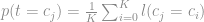
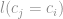

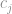 é igual a soma das ocorrências positivas dividida pela quantidade de vizinhos mais próximas da instância.
é igual a soma das ocorrências positivas dividida pela quantidade de vizinhos mais próximas da instância.
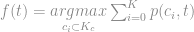
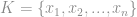
 :
:
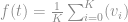

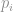 é o peso de cada valor real
é o peso de cada valor real  associado ao vetor
associado ao vetor  dos vizinhos mais próximos.
dos vizinhos mais próximos.